
Configuring AI servers for high-demand applications is part science, part craft. The science is in sizing compute, memory, storage, and networking to match throughput and latency goals. The craft is in tuning kernels, orchestrating workloads, and designing resilient pipelines that keep GPUs busy while controlling cost.
In this guide, we unpack practical, up-to-date steps for configuring AI servers for high-demand applications in production—covering hardware choices, cluster design, software stacks, data paths, observability, security, compliance, and cost management.
We’ll keep paragraphs lean and readable while going deep enough to be useful for architects, MLOps leads, and platform engineers who must deliver reliable performance at scale.
Define the Workload and SLOs Before You Buy or Build

Every configuration choice flows from workload profile and service objectives. For configuring AI servers for high-demand applications, start with explicit targets: median and tail latencies (P50/P95/P99), requests per second, concurrency, and batch sizes.
Clarify if the workload is training, fine-tuning, retrieval-augmented generation, online inference, or feature extraction. For LLM inference, model size, quantization level, and prompt/response lengths drive memory and compute needs.
For vision or speech, pre- and post-processing can dominate CPU and memory bandwidth. Establish SLOs around availability (e.g., 99.9%), durability, and recovery time so you can design capacity headroom and failover paths.
Translate objectives into resource envelopes. For training, measure tokens/sec or samples/sec per GPU at desired precision (FP32/TF32/FP16/BF16/INT8). For inference, estimate GPU memory per model shard, KV cache footprint, and per-request compute. Plan concurrency by mapping sessions to GPU instances or MIG slices.
For configuring AI servers for high-demand applications you must also forecast growth: new models, larger contexts, and higher request volumes. Bake in burst capacity mechanisms—autoscaling, queue depth thresholds, and traffic shedding policies—so you can protect latency under spikes without overspending.
Choose Compute: GPUs, CPUs, and Accelerators That Fit the Job
When configuring AI servers for high-demand applications, GPUs are usually the centerpiece, but CPUs, memory bandwidth, and interconnects decide real-world throughput. If training large models or serving many concurrent sessions, favor GPUs with high HBM capacity and bandwidth.
For inference at scale, evaluate tensor-core performance for low-precision formats (BF16, FP8, INT8) and the maturity of quantization toolchains. Consider partitioning via MIG to allocate smaller, isolated GPU slices to latency-sensitive microservices.
CPUs still matter. Tokenization, data decoding, streaming I/O, and vector DB queries can saturate cores. Choose high-frequency CPUs with ample L3 cache when pre/post-processing or cryptography is in the hot path.
Size system RAM so the OS, page cache, and CPU operators avoid swapping; 2–4× aggregate GPU memory is a common baseline. For configuring AI servers for high-demand applications, accelerators beyond GPUs—like smartNICs with DPUs or FPGAs—can offload TLS, storage, or inference prefetch, reducing jitter and freeing CPU cycles.
Match PCIe generations (Gen4/Gen5) and lane counts to avoid bandwidth bottlenecks between GPUs, NVMe, and NICs.
Architect the Cluster: Scale-Up, Scale-Out, and Interconnects
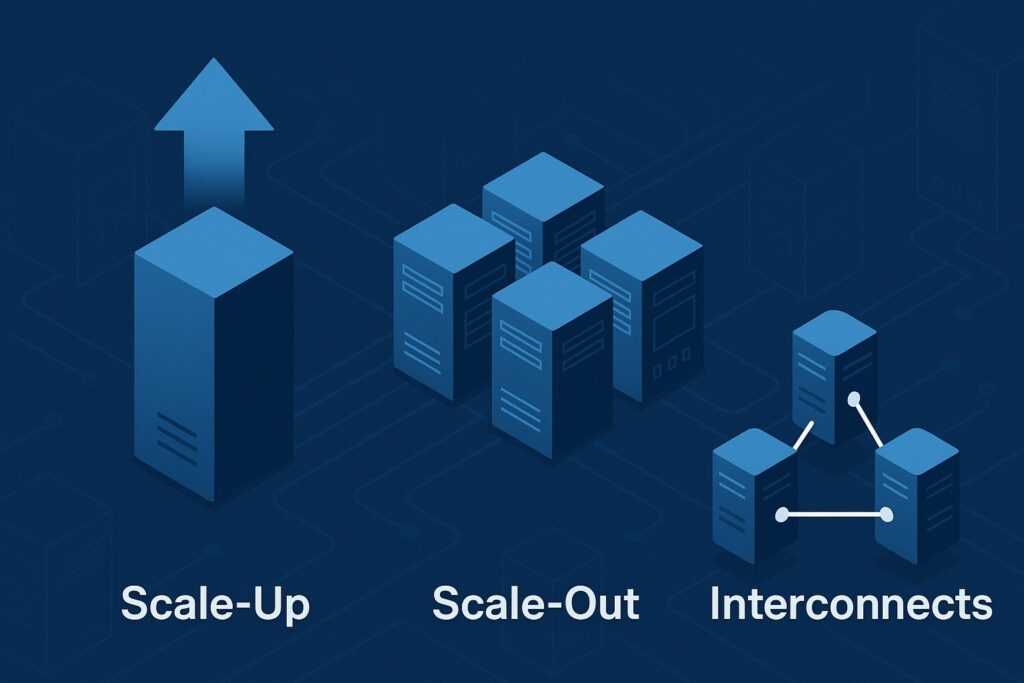
A single powerful box can be great for low-latency inference, but high-demand traffic often requires clusters. Configuring AI servers for high-demand applications means choosing between scale-up nodes with many GPUs and scale-out fleets with fewer GPUs per node.
Scale-up simplifies intra-node communication and can accelerate tensor parallel training or multi-GPU inference with large KV caches. Scale-out improves blast radius and incremental scaling but makes collective communication and state management harder.
Interconnects shape the ceiling. Within a node, NVLink or similar high-bandwidth fabrics reduce all-reduce overheads; across nodes, 100–400 Gbps Ethernet or Infiniband affects gradient sync and model sharding.
For inference, low-latency service meshes, efficient RPC (gRPC/HTTP2), and well-tuned TCP stacks reduce tail latencies. Partition traffic across availability zones for resilience.
For configuring AI servers for high-demand applications, keep the control plane simple: Kubernetes or Nomad for scheduling, with node pools for GPU, CPU, and cache tiers. Isolate noisy neighbors through resource quotas, priority classes, and network QoS.
Storage and Data Paths: Feed GPUs Without Starving Them

GPUs stall when input pipelines can’t keep up. When configuring AI servers for high-demand applications, design storage to deliver high parallel read IOPS and throughput. Use NVMe SSDs for hot model weights and KV cache spill; ensure PCIe lanes are not oversubscribed.
For large corpora, pair object storage with local SSD caching. Pre-shard or pre-pack data into contiguous blocks to minimize random I/O overhead during training. Enable asynchronous prefetch and pin memory for zero-copy transfers where supported.
Separate write-heavy telemetry and cold archives from latency-sensitive paths. If using a vector database for retrieval, benchmark HNSW/IVF/ScaNN settings with your embedding distribution. Co-locate vector indexes and embedding services when possible to reduce cross-AZ hops.
For configuring AI servers for high-demand applications, enforce backpressure: if upstream can’t supply batches fast enough, adapt micro-batch sizes or batch windows so GPUs stay saturated but latency SLOs are honored. Monitor disk queue depth, page cache hit rate, and DMA engine utilization to detect starvation early.
Build a Clean, Reproducible Software Stack
A reliable stack is repeatable. Use a minimal, hardened Linux base with recent kernels for IOMMU, NVMe, and GPU driver stability. Containerize everything. For configuring AI servers for high-demand applications, pin CUDA/ROCm versions and set deterministic build flags.
Maintain golden images with tested driver, runtime, and library combos. Keep separate images for training and inference: inference images should be thin, cold-start fast, and include only the necessary runtimes, tokenizer assets, and kernels.
Adopt orchestrators that handle GPU scheduling natively. Use device plugins, node labeling, and topology-aware scheduling to place pods on the right NUMA/GPU topology. Implement configuration as code: Helm charts, Terraform modules, and policy-as-code for network and security.
For configuring AI servers for high-demand applications, standardize on model servers (e.g., TensorRT-based or PyTorch-based) that support dynamic batching, paged attention, and multi-model loading. Expose a clean, versioned API with schema and rate limits so downstream teams can integrate predictably.
Tune for Inference: Precision, Batching, and KV Cache Strategy
Inference is where most production load lives. For configuring AI servers for high-demand applications, select the lowest precision that preserves quality: BF16 or FP16 for high fidelity, FP8/INT8 with per-channel scales for maximum throughput.
Calibrate quantization with representative datasets, and validate safety and hallucination rates. Use paged attention or block-sparse attention to keep memory linear with sequence length. Size KV caches carefully; reuse them for streaming and multi-turn sessions to avoid recomputing context.
Dynamic batching is powerful when tuned. Bound batch windows in milliseconds to cap latency while raising GPU occupancy. Consider request bucketing by sequence length. For multi-tenant clusters, partition GPUs via MIG and enforce per-tenant quotas for cache memory.
For configuring AI servers for high-demand applications, exploit speculative decoding or assisted generation where supported to cut latency without quality loss. Cache frequent prompts/responses at the edge with ETags and TTLs to reduce GPU hits for common templates and system prompts.
Optimize Training: Parallelism, Checkpointing, and Throughput
Training large models stresses communication and I/O. When configuring AI servers for high-demand applications that include training or continual fine-tuning, choose a parallelism strategy that matches your hardware: data parallel for many nodes, tensor/pipeline parallel for big models, and optimizer sharding to reduce memory.
Use gradient compression or mixed precision to cut bandwidth. Align batch sizes to saturate tensor cores while meeting stability targets. Profile input pipelines; decode, augment, and tokenize on CPUs with vectorized libraries, and prefetch to GPU.
Checkpointing must be reliable and fast. Write incremental or partitioned checkpoints to NVMe, then replicate to object storage asynchronously. Use resumable training and deterministic seeds for reproducibility.
For configuring AI servers for high-demand applications, embed performance tests in CI/CD: run small synthetic steps to validate kernels after driver updates. Track tokens/sec per GPU and time-to-target metric, not just loss curves; these tell you if a cluster regression sneaked in.
Networking: Latency, Throughput, and Service Mesh Hygiene
Your network is a distributed system’s nervous system. For configuring AI servers for high-demand applications, start with sufficient NIC bandwidth per node. Enable RSS, tune ring buffers, and verify jumbo frames where beneficial.
Pin IRQs and balance receive queues across CPU cores that are not handling heavy userland work. Use gRPC with HTTP/2 and connection pooling; avoid excessive TLS session renegotiation by enabling session resumption.
At the service layer, adopt a mesh only if you need it. Sidecars add latency and resource overhead; consider mesh-less mTLS for hot paths. If you do use a mesh, exclude GPU data planes from noisy neighbors and set circuit breakers on upstreams.
For configuring AI servers for high-demand applications, prioritize AZ-local routing, configure outlier detection to eject slow endpoints, and expose readiness/liveness probes that actually reflect model readiness (e.g., a dummy forward pass).
Observability and SRE: See Problems Before Customers Do
High-demand platforms require deep visibility. Instrument everything: GPU utilization, memory, HBM bandwidth, SM occupancy, kernel times, and NVLink saturation. Collect CPU load, NUMA locality misses, and run queue lengths.
At the application level, trace request life cycles: tokenization, model invocation, KV cache hits, and streaming. For configuring AI servers for high-demand applications, export per-tenant metrics, and separate system health SLOs from model quality KPIs (e.g., toxicity or refusal rates).
Alert on symptoms, not just causes. Page on elevated P95 latency, rising error budgets burn, and abnormal queue depths. Automate remediation: cordon bad nodes, restart poisoned drivers, fail over to a warmed spare model, or reduce max tokens to protect latency.
Chaos tests regularly. Run game days that simulate GPU loss, storage brownouts, or traffic spikes so playbooks are tested. Keep postmortems blameless and track action items with owners and dates.
Security, Governance, and Compliance From Day One
Production AI often touches sensitive data. When configuring AI servers for high-demand applications, enforce least privilege at every layer: IAM roles for workloads, signed images, and policy-as-code for network access.
Encrypt data in transit with modern ciphers and at rest with KMS-managed keys. Use hardware-rooted attestation where available. Rotate credentials and use short-lived tokens for services.
Governance matters. Maintain a model registry with lineage: datasets, training code commits, hyperparameters, and evaluation reports. For configuring AI servers for high-demand applications, implement content filters and safety guardrails aligned with your domain’s policies.
Log prompts and outputs with redaction rules and retention limits. If you must meet regulatory frameworks (e.g., SOC 2, ISO 27001, HIPAA, or GDPR), map controls to platform features and document evidence. Make privacy reviews part of the release checklist.
Cost Management: Performance per Dollar as a First-Class Metric
A great performance that bankrupts you isn’t success. For configuring AI servers for high-demand applications, monitor cost per token, cost per thousand requests, and GPU dollars per hour used versus allocated.
Right-size instances and prefer spot or preemptible capacity for stateless or resilient jobs. Use autoscaling on concrete signals: GPU busy percent, queue length, and request rate. Schedule heavy batch jobs for off-peak windows when prices drop.
Reduce waste. Consolidate small models on shared GPUs with MIG, or move light workloads to CPU when feasible. Quantize models to shrink memory and increase throughput. Aggressively cache static content and common responses.
For configuring AI servers for high-demand applications, adopt budget alerts and chargeback/showback by team or tenant to make cost visible. Build a culture where engineers profile before scaling out.
Deployment Patterns: Edge, Hybrid, and Multi-Region
User experience can hinge on geography. For configuring AI servers for high-demand applications, put latency-sensitive inference close to users via edge POPs or regional GPU clusters.
Use edge caching for prompts and static embeddings, and route only the model invocation to GPU regions. In hybrid setups, keep sensitive data on-prem with secure tunnels to cloud GPUs for burst capacity. Design multi-region active-active for read-heavy inference, and active-passive for training or stateful services.
Traffic management matters. Use global load balancers with health checks keyed to real service readiness. For configuring AI servers for high-demand applications, implement weighted or geo-based routing to steer traffic during incidents or A/B tests.
Warm standbys with model weights pre-loaded so failover doesn’t incur cold starts. Replicate feature stores and vector indexes asynchronously, and tolerate eventual consistency where product allows.
Benchmarking and Validation: Trust but Verify
Never assume performance—measure it. Build reproducible benchmarks that mirror production payloads: real prompt lengths, user concurrency, and mixed traffic.
For configuring AI servers for high-demand applications, capture both throughput and tail latency, and include soak tests to surface memory leaks or fragmentation. Evaluate the impact of quantization on quality with human-in-the-loop checks and domain-specific metrics.
Validate resilience. Kill a GPU mid-run. Drop an AZ. Throttle storage. Confirm your autoscalers, backpressure, and retries do what you expect. For configuring AI servers for high-demand applications, record baselines for each image version and driver combo.
If a change regresses performance by more than a small budget, block the release. Keep benchmark dashboards visible so regressions are obvious and conversations are grounded in data.
Lifecycle, Maintenance, and Upgrades Without Disruption
Change is the only constant. For configuring AI servers for high-demand applications, adopt blue/green or canary rollouts for drivers, runtimes, and model servers. Keep two production-ready images: current and next.
Drain nodes gracefully, migrate sessions, and verify health before shifting traffic. Document rollback steps and keep last-known-good artifacts cached locally in case your registry is down.
Hardware ages. Monitor ECC error rates, SSD wear, and thermal margins. Replace before failures spike. For configuring AI servers for high-demand applications, run periodic kernel and firmware updates during maintenance windows, and test them in staging under production-like load.
Clean up stale containers, prune old model versions, and rotate logs so disks don’t fill. Lifecycle management keeps platforms predictable, safe, and fast.
Practical Configuration Checklist (Condensed)
- Define SLOs, traffic shape, and growth forecast.
- Pick GPUs for precision needs; size CPU, RAM, and PCIe lanes.
- Choose interconnects (NVLink, 200–400 Gbps) aligned to parallelism.
- Use NVMe for hot weights and caches; object storage for cold.
- Standardize, containerize, and pin runtime versions.
- Tune precision, batching, and KV caches; enable paged attention.
- Instrument deeply; alert on tail latency and error-budget burn.
- Enforce least privilege; encrypt, attest, and log with governance.
- Optimize cost per token; prefer spot where safe.
- Go multi-region with warmed standbys; test failovers.
- Benchmark every change; canary and roll back if needed.
FAQs
Q.1: What’s the most common bottleneck when configuring AI servers for high-demand applications?
Answer: It’s often the data path. GPUs sit idle while input pipelines decode, tokenize, or fetch from slow storage. Fixes include parallelized tokenization, NVMe caches, DMA-friendly memory pinning, and batching tuned to your latency envelope. Network jitter, not GPU speed, is another frequent culprit, especially across AZs.
Q.2: How do I decide between BF16, FP16, FP8, or INT8 for inference?
Answer: Start with BF16/FP16 for fidelity, then test FP8/INT8 with proper calibration to quantify quality loss. If business metrics hold steady, lower precision yields higher throughput and lower cost. Always validate safety, toxicity, and helpfulness scores—not just perplexity.
Q.3: Do I need a service mesh for configuring AI servers for high-demand applications?
Answer: Not always. Meshes add features but also latency and complexity. For hot inference paths, many teams prefer direct mTLS with a lightweight gateway and well-tuned gRPC. Use a mesh where policy, traffic shaping, or observability demands it.
Q.4: How should I handle model versioning in production?
Answer: Maintain a registry that records code commit, dataset lineage, hyperparameters, quantization level, and evaluation results. Route a small percentage of traffic to canaries, compare metrics, then promote. Keep at least one prior version hot for instant rollback.
Q.5: What’s the best way to control costs without hurting reliability?
Answer: Measure cost per request and per token alongside P95 latency. Use dynamic batching, quantization, and MIG slices to increase utilization. Autoscale on GPU busy time and queue depth. Reserve capacity for base load and use spot or burst pools for spikes.
Conclusion
Configuring AI servers for high-demand applications is a disciplined exercise in aligning hardware, software, and operations to crystal-clear SLOs. It starts with realistic workload modeling and ends with relentless measurement in production.
The best architectures pair fast GPUs with balanced CPUs, high-bandwidth interconnects, and NVMe-backed data paths. They run on clean, version-pinned stacks; use batching, quantization, and KV cache strategies to keep latency tight; and rely on deep observability to stay healthy under stress.
Security and governance are woven in, not bolted on, and cost is treated as a first-class metric. If you approach configuring AI servers for high-demand applications as a continuous loop—benchmark, deploy, observe, optimize—you’ll deliver performance your users can feel and reliability your business can bank on.