
By hostmyai September 29, 2025
Real-time conversational AI has leapt from novelty to necessity. Customers expect instant, helpful, and context-aware responses on every channel—web, mobile, voice, kiosk, IVR, even in-store POS systems.
Behind the scenes, delivering that “it just talks back” magic depends on hosting platforms built to keep latency low, availability high, data secure, and costs predictable as your traffic ebbs and spikes.
This guide dives deep into the hosting choices for production-grade chatbots, voice agents, and multimodal assistants, explaining architectures, trade-offs, and the nitty-gritty of making systems fast and reliable at scale.
We’ll demystify the stack—from GPUs and model servers to vector databases, observability, and edge networks—and show you how to align platform choices with your latency SLOs, privacy constraints, and budget.
At a minimum, a real-time assistant must accept user input, run inference on one or more models, enrich responses with tools/data, and return results within tight time windows (100–800 ms for interactive UI updates; 1–2 seconds for more complex multi-tool flows; 200–400 ms per token for streaming TTS).
The platform you pick is the difference between a silky, streaming experience and a laggy back-and-forth that users abandon.
Choosing well means thinking about more than GPUs: e.g., do you need on-prem because regulated data can’t leave your VPC? Will you serve a single large model, or a fleet of smaller specialized models behind a router? Should you prioritize per-token price, or minimize tail latency? Can you cache outputs or embeddings to cut costs without degrading quality?
Each decision ripples through your architecture, affecting observability, versioning, rollback, and incident response when things go sideways.
In this article, we’ll compare managed AI clouds, DIY Kubernetes in your VPC, hybrid/edge designs, and fully on-prem clusters.
We’ll examine model hosting patterns (LoRA-adapted LLMs, distilled variants, mixture-of-experts, reranking stacks for retrieval), and how to wire in streaming ASR/TTS for voice.
You’ll see how to budget the latency of every step—tokenization, KV-cache warmup, retrieval, function calls, guardrails—and what knobs actually move the needle (batching, speculative decoding, quantization, tensor/kv offload, and prompt caching).
We’ll also cover security (PII, SOC2/ISO/PCI scope), reliability (multi-AZ, graceful degradation), cost controls (autoscaling, right-sizing GPUs, spot/interruptible nodes), and a pragmatic build-vs-buy decision framework.
Whether you’re upgrading a web chatbot or launching a 24/7 call-center agent, this end-to-end guide equips you to choose and run the right platform with confidence.
What “Real-Time” Really Means for Conversational AI (and Why It’s Hard)

“Real-time” is not a single number; it’s a set of experience thresholds. For text chat in a browser, users notice delay at ~300–500 ms before the first streamed token. For voice, latency stacks: capture → ASR → NLU/LLM → tools → NLG → TTS → playback.
Even small inefficiencies compound until your agent feels sluggish or speaks over the user. Practically, you’re aiming for sub-300 ms ASR partials, <1 s first-token latency from the model, and <250 ms TTS chunk turnaround for natural turn-taking.
That’s the human-perceived bar; your infrastructure must be faster to leave headroom for network variance, queueing, and downstream APIs.
Why is this hard? First, stateful models (LLMs with long context) keep KV caches and benefit from warm instances; cold starts are killers. Second, prompt construction and retrieval add hops—vector searches, metadata filters, rerankers, and tool calls introduce non-deterministic latency.
Third, models are sensitive to batch sizes and request patterns: you can cut costs with batching but risk tail latency spikes when a few big prompts stall a batch. Fourth, voice requires bidirectional streaming and partial results; you can’t block on full transcripts or synthesized audio.
Finally, observability lags behind web norms: measuring tokens/sec, time-to-first-token (TTFT), per-stage latency, and cache hit rates across multi-model graphs is non-trivial.
To deliver consistently, define explicit SLOs (e.g., TTFT p95 < 800 ms, response p95 < 2.5 s) and budget the path: input capture (20–50 ms), gateway auth/routing (5–20 ms), retrieval (80–200 ms), model TTFT (250–800 ms), streaming decode (10–30 ms/token), post-processing (20–60 ms), egress (30–80 ms).
Adopt streaming everywhere (ASR partials, LLM tokens, TTS segments). Keep computers close to users or telephony POPs to avoid WAN RTT penalties. And expect real-world variance: plan for tail handling via dynamic batching limits, priority queues for voice, and circuit breakers when tools slow down.
Core Hosting Options: Managed AI Clouds vs. Private VPC vs. On-Prem
Most teams choose among three broad patterns: (1) fully managed AI platforms (vendor-hosted models with simple APIs), (2) private VPC hosting on your cloud (EKS/AKS/GKE + model servers you operate), or (3) on-prem/edge clusters for strict data control or low-latency voice.
Managed platforms shine for speed-to-value: no GPU ops, instant access to optimized inference, model upgrades, and features like prompt caching, vector stores, evals, and safety filters.
The trade-offs are data residency, cost predictability at scale, and limited control over kernels/quantization. Private VPC offers stronger control and compliance alignment—you keep data and logs in your accounts, integrate with your IAM/KMS, and tailor autoscaling and caching.
But you inherit the toil: GPU node pools, driver/toolkit drift, rolling upgrades, and incident response at 3 a.m. On-prem delivers maximum sovereignty and potentially the lowest unit latency for telephony gateways or in-store devices, yet requires deep bench strength in hardware lifecycle, cluster orchestration, and capacity planning.
A practical hybrid is common: latency-critical voice agents run close to carriers/edge regions, while general chat uses managed APIs. Sensitive prompts get processed in your VPC (e.g., PII redaction, encryption), with de-identified context sent to a managed LLM.
Another hybrid pattern: bring-your-own-key (BYOK) or ephemeral retention modes to retain control over data, paired with per-tenant prompts encrypted under your KMS.
Whatever you pick, weigh contractual guarantees—SLA/SLOs, data processing addenda (DPA), model retention policies, and security attestations—against the value of turnkey scaling and new model access.
The inflection points are usually volume (tokens/day), compliance (e.g., PCI scope), and the need for custom fine-tuning or deterministic behavior you can’t get from a shared SaaS.
Building a Latency Budget and Meeting It in Production

Before you pick hardware or a provider, write down your latency budget by channel. For voice, define a target like: user speaks → partial ASR within 150–250 ms; LLM TTFT < 600 ms; first TTS audio < 800–1,000 ms; barge-in supported (the user can interrupt).
For web chat, aim for TTFT < 700 ms and a smooth 15–30 tokens/sec. Then enumerate every step in your pipeline and assign caps. Measure in staging with real traffic patterns, not synthetic micro-benchmarks.
Tokenization can be tens of milliseconds for huge prompts; prompt assembly with tool outputs and formatting can add more. Retrieval isn’t “free”: vector search (even fast HNSW/IVF) plus reranking (cross-encoders) can consume 100–200 ms.
Tools such as product catalogs, CRMs, or payment gateways vary wildly—wrap them with timeouts, backoff, and cached fallbacks. For TTS, prefer streaming APIs that start speaking after the first sentence rather than producing the whole waveform first.
Meeting your budget is about trade-offs and guardrails. Use streaming everywhere—don’t wait to finish retrieval if you can send a greeting token immediately. Make model choice dynamic: large models for tough queries, smaller distilled/ instruction-tuned models for routine flows.
Apply speculative decoding (draft models) to reduce TTFT and boost tokens/sec. Warm KV caches with short “hello” prompts; keep hot pools per locale or tenant. Cap context length to what your retrieval genuinely needs; over-long prompts balloon TTFT.
Cache aggressively: retrieval results for common queries, embeddings for frequent documents, tool outputs for stable catalog data, and even full responses (with cache keys that consider user permissions).
Finally, track p95/p99—not just averages—and enforce SLOs with admission control (shedding low-priority requests) during spikes to protect your real-time channels.
Model Serving Patterns and Orchestration for Conversations
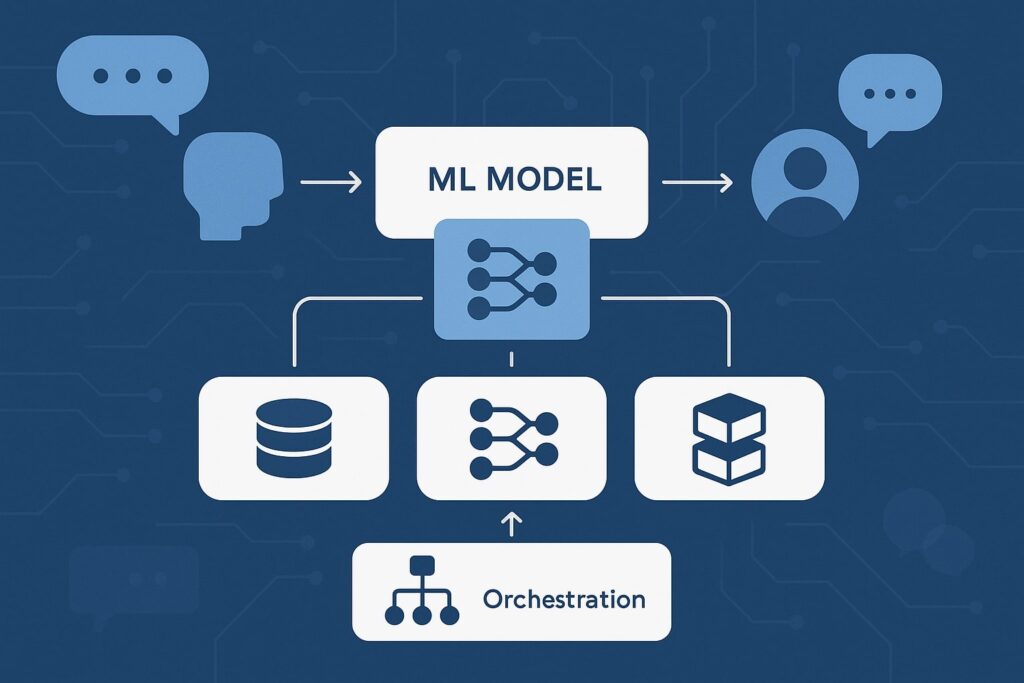
Serving a single monolithic LLM is rarely optimal for real-time agents. Instead, build a model graph. A typical pattern: a lightweight intent classifier or small LLM routes requests; a retrieval step augments context; a main model generates responses; specialized models handle sub-tasks (math, code, extraction); a reranker improves grounded answers; a guardrail model screens outputs.
For voice, add ASR before and TTS after, ideally both streaming. The router can be rules-plus-ML: fast regex/intents for obvious flows (balance checks, FAQs), and a small LLM for ambiguous prompts.
The main model can switch by complexity threshold or user tier—e.g., 7–14B parameter models for routine, 70B+ for complex reasoning.
Fine-tuning options include LoRA adapters for domain tone or tools usage, instruction tuning to reduce hallucinations, and RAG-first designs that keep the base model general while your knowledge stays in vector stores.
Quantization (INT8/FP8/INT4) yields big throughput gains; mix with tensor parallelism and KV-cache offload (CPU/NVMe) for long contexts. Speculative decoding uses a faster “draft” model to propose tokens that a stronger “target” model verifies, cutting TTFT without major quality loss.
For orchestration, consider a graph runtime that supports streaming edges, retries, and timeouts per node, with tracing baked in (spans, tokens/sec, cache hits, tool latencies). Keep versions immutable and roll forward behind feature flags; conversational behavior changes can surprise users and agents if you swap models without guardrails.
Routing Strategies that Balance Quality, Cost, and Latency
At scale, cost and performance hinge on smart routing. Start with a coarse triage: (1) trivial intents answered by a retrieval + small model; (2) moderate tasks (multi-turn questions, policy queries) sent to a mid-size model; (3) rare complex queries escalated to a large SOTA model.
Implement budget-aware routing: each request carries a soft token budget and latency limit; the router selects a path expected to stay within both. Incorporate confidence signals: if retrieval returns low-scoring passages, use a stronger model or ask a clarifying question to avoid low-quality answers.
Add user tiering: premium users or revenue-critical workflows can unlock higher caps. For voice, maintain a “fast lane” that strictly disallows slow tools and long contexts; if the agent needs heavy research, switch to a call-back or send a follow-up message.
Routing must remain adaptive. Track real outcomes—deflection rates, CSAT, escalation frequency, containment—and feed these signals into route selection. Periodically re-train the intent classifier and update thresholds as your knowledge base grows.
Keep an override: operators can pin routes during incidents (e.g., disable the large model if its TTFT spikes). Finally, cache route decisions for short windows; users often ask follow-ups of the same type, and consistent routing improves predictability and cost.
Prompt Engineering and Context-Window Hygiene for Speed
Long prompts kill TTFT and raise costs. Enforce strict prompt budgets and templates: system prompt (concise guardrails + role), condensed conversation memory (summaries not transcripts), top-N retrieval (3–5, not 20), and compact tool schemas.
Replace verbose formatting with JSON grammar constraints or tool-calling modes to shrink tokens. Summarize older turns as the conversation grows; keep only the last user intent plus snippets of relevant facts. Use server-side prompt assembly to avoid client stalls and to reuse components.
Keep stop-word lists for retrieval to avoid irrelevant matches; use per-tenant filters to narrow embeddings search space. When possible, place static instructions in a short system prompt and keep dynamic details in tools; the model can ask for the tool output only when needed.
RAG, Guardrails, and Evals that Don’t Break Real-Time
Retrieval-augmented generation (RAG) improves truthfulness, but poorly tuned RAG slows you down. Pick a vector index (HNSW/IVF/SQ) and tune it for recall vs. latency; pre-compute embeddings for hot content; shared by tenant and topic.
Add a reranker only if it boosts accuracy materially—cross-encoders can add 50–150 ms; measure whether they pay for themselves. Guardrails should be lightweight: regex/pattern filters for known policies; a small classifier for safety categories; selective heavier checks only when high risk is detected.
Evals must run offline, but instrument online quality: ask users for thumbs-up/down, track rephrases, and sample sessions for human review. Periodically replay anonymized logs against new model candidates and measure both quality and timing.
Real-time systems live or die by tail latency; never bolt on new quality checks without measuring their latency and impact.
Inference Acceleration: Hardware, Quantization, and Throughput Tricks
Hardware choice drives unit economics. For transformer LLMs, modern GPUs with larger HBM (e.g., 80 GB) enable bigger batch sizes and keep KV caches resident, boosting tokens/sec.
Multi-GPU inference relies on tensor/pipeline parallelism; choose frameworks that hide complexity while exposing useful knobs (batch size, sequence parallelism, paged attention).
CPU-only paths can work for small 1–3B models or for lightweight rerankers, but they struggle with larger contexts and real-time TTFT.
Quantization (INT8, FP8, INT4) reduces memory footprint and increases throughput with minimal quality loss if done carefully; combined with grouped-query attention, flash attention, and Efficient KV.
For voice, ASR/TTS benefit hugely from GPU acceleration when doing streaming, but edge cases (on-device TTS) can run well on optimized CPUs or NPUs.
Achieving throughput without harming latency is an art. Dynamic batching aggregates requests within a few milliseconds to fill the GPU, but keep your max batch wait tight (e.g., 2–10 ms) for real-time flows.
Separate traffic classes: “interactive” queues with tiny batch windows and “batch/assist” queues that can wait longer. Use speculative decoding—a smaller draft model predicts multiple tokens, the main model verifies—to cut TTFT and increase tokens/sec.
Offload KV caches to CPU/NVMe when contexts are long, but beware PCIe bandwidth; for voice agents keep contexts short and rely more on dialogue state machines than giant transcripts.
Prompt caching (dedupe identical prompts, or reuse partial prefixes) pays off in FAQs and system prompts. Finally, keep a warm pool of model replicas for zero cold starts; pre-load LoRA adapters for your top tenants to avoid hot-swap stalls.
Networking and Edge Considerations for Voice and Multimodal
The network is part of your latency budget. For WebRTC or SIP voice, place computers near telephony POPs to minimize round-trip. Use UDP-friendly media paths and SRTP where required; terminate TLS close to the client.
Prefer bi-directional streaming transports (WebSockets/HTTP2 gRPC) so ASR/LLM/TTS can all stream concurrently. If your user base is global, deploy regional shards and state synchronization: conversation state (summaries, slots, user profile) should replicate quickly but compactly.
Apply jitter buffers and barge-in logic on the client to create natural interruptions. For browser chat, HTTP/2 or WebSocket streaming is critical—users should see the first token fast and a steady cadence thereafter.
Edge runtime can host simple pre-processing: profanity/PII detection, language identification, input normalization, and even small-model intent classification. Keep the heavy lifting (LLM, RAG, TTS) in GPU regions, but shave 50–100 ms off the path by handling the trivial at the edge.
CDN and DNS decisions also matter; co-locate API gateways with inference regions, enable keep-alive and TLS session resumption, and limit cross-region chatter (e.g., don’t call a US vector DB from an EU inference pod).
For mobile, compress audio with low-latency codecs and tune packet sizes to balance quality vs. delay. Measure end-to-end with real users: synthetic tests miss carrier quirks, NAT timeouts, and device throttling that appear at scale.
Data, Memory, and Personalization Pipelines
Conversational quality jumps when agents remember users and personalize answers, but memory must be deliberate. Use short-term memory (last intent, entities, unresolved tasks) within the session for speed, and long-term memory (preferences, past orders, account flags) persisted in your core DB.
Keep the LLM context slim by summarizing histories and storing facts as structured attributes the model can fetch via tools. For knowledge grounding, maintain a content pipeline: ingest docs, chunk smartly (semantic boundaries), embed with a model suited to your domain, and tag metadata (tenant, locale, recency).
Refresh frequently for time-sensitive data (pricing, inventory), and expire stale vectors to reduce drift. Add a reranker if your domain demands precision (legal, medical), but budget its latency.
Personalization must respect privacy. Keep PII encrypted at rest with your KMS, minimize what enters prompts, and mask/format before logging. For multi-tenant systems, enforce row-level security on vectors and tools.
Run redaction before any third-party call when policy requires it. Audit who can see prompts and responses, and segregate logs by tenant. For quality operations, sample a subset of sessions and strip identifiers.
As you evolve, build offline evaluation sets that mirror your users’ intents; re-run them whenever you change models, prompts, or retrieval to prevent regressions.
Reliability Engineering for AI Agents
Availability is as critical as latency. Architect for failure by isolating dependencies and offering graceful degradation. Run multiple model replicas across zones; use health probes that test actual token generation, not just container liveness.
When your vector DB slows, switch to a small local cache of top FAQs; when TTS is impaired, fall back to text in chat or a “please hold” message in voice rather than dead air. Circuit breakers around tools protect your SLOs—if the CRM is timing out, answer with partial information and a promise to follow up.
Keep automatic retries idempotent and bounded; duplicate tool calls can create side-effects (e.g., double refunds) if you’re not careful.
Operational excellence requires observability tailored to AI. Collect per-request spans: TTFT, decode rate, tokens in/out, cache hits, retrieval timing, tool calls, TTS chunking.
Track SLOs (p95 TTFT/latency, error rates) and alert on anomalies (e.g., tokens/sec drops on one GPU type). Canary new model versions on 1–5% of traffic behind a flag. Keep a fast rollback (immutable versions).
Maintain playbooks for GPU node drains, driver rollbacks, and model server restarts. Finally, perform chaos drills: kill a region, throttle the vector DB, or spike ASR errors to ensure your fallbacks actually work in production.
Security, Compliance, and Data Governance for Conversational AI
Security posture spans the whole pipeline: identity (OAuth, mTLS between services), secrets (KMS, short-lived tokens), data handling (prompt encryption, PII redaction), and vendor governance.
In regulated contexts (PCI, HIPAA), decide whether prompts/responses place systems in scope and isolate components accordingly. Use VPC peering/private links to external services where possible; avoid public egress for sensitive data.
Implement least-privilege IAM for model servers and storage; rotate credentials automatically. Encrypt prompts and outputs at rest; if you send data to a third-party LLM, enable ephemeral retention or opt-out of training, and document those settings in your DPA.
For auditability, log what matters without over-collecting: model/version, prompt template version, retrieval sources (doc IDs), tool calls (names, not raw PII when avoidable), and user consent flags.
Provide data subject rights tooling (export/delete) if you store conversation histories. Mask card numbers, SSNs, or health identifiers before they touch a prompt; consider using specialized PCI-proxy or tokenization services for payment flows so that your AI layer remains out of PCI scope.
Educate stakeholders about the limitations of the model and place policies in the system prompt—e.g., never invent invoice amounts; refuse to disclose PII; escalate if fraud indicators exceed a threshold.
Cost Management Without Sacrificing Experience
Costs grow with traffic, tokens, and model choice. Start with visibility: per-tenant/token cost, per-route cost, idle GPU burn. Put budgets into routing: use smaller models for routine, cache aggressively, and cap maximum output tokens.
Adopt prompt-engineering discipline to shrink context. Reserve capacity (committed-use GPUs or discounted API tiers) for baseline load; autoscale for peaks with spot/interruptible nodes where safe.
Separate real-time from batch analytics workloads so batch doesn’t starve your interactive queues. Evaluate quantized or distilled models; many customer-service tasks work well on mid-size models with guardrails plus good retrieval.
Consider architectural levers: speculative decoding can cut cost by allowing higher throughput per GPU; LoRA adapters reuse one base model across tenants rather than hosting many fine-tuned variants; shared vector indexes per tenant reduce duplication.
For managed platforms, enable features like prompt/result caching and negotiated enterprise plans with predictable pricing and retention controls. Finally, run periodic cost/quality reviews: sample real conversations, try alternative routes/models, and verify you’re not paying for unnecessary capacity or extravagant prompts.
Build vs. Buy: A Pragmatic Decision Framework
There’s no universal right answer—only trade-offs. You should learn “buy” (managed AI platform) if you need speed to market, lack GPU operations expertise, want access to cutting-edge models without managing kernels, and can work within data-handling constraints (ephemeral retention, masking).
You should learn “build” (your VPC/on-prem) if data can’t leave your environment, you need deterministic performance/behavior, or unit economics at your scale favor owning the stack.
Many teams split the difference: a managed provider for general chat and a VPC-hosted stack for sensitive flows, or a managed LLM plus self-hosted retrieval and tools.
Use a scorecard across axes: latency SLOs, data residency/regulatory requirements, volume (tokens/day), required model flexibility (fine-tuning, adapters, control over quantization), internal ops maturity, and budget predictability.
Run small, production-like pilots for each candidate path and measure end-to-end latencies, tail behavior, and quality—not just synthetic benchmarks. Negotiate DPAs and SLAs early, and ensure exit plans: can you export conversation logs, prompts, embeddings, and adapters if you switch vendors? Document a migration path even if you don’t intend to use it soon.
Evaluation Checklist for Choosing an AI Hosting Platform
Use this checklist when you talk to vendors or design your own stack:
- Latency: TTFT p95, streaming support, multi-region presence, edge options.
- Throughput: tokens/sec per replica, dynamic batching, speculative decoding.
- Reliability: multi-AZ, failover, circuit breakers, warm pools, SLA specifics.
- Observability: request tracing, token metrics, cache stats, per-stage timings.
- Models: choice and version control, adapters/LoRA, quantization options, routing support.
- RAG: native vector DB, retrieval latency, reranker options, ingestion pipelines.
- Safety: guardrails, PII policies, configurable refusal behavior.
- Data controls: retention settings, BYOK/KMS, VPC peering/private link, logging controls.
- Pricing: per-token/per-minute rates, caching discounts, committed-use options.
- Tooling: function calling, schema enforcement, evals, A/B testing, canary releases.
- Voice: streaming ASR/TTS, barge-in, telephony integrations, jitter buffers.
- Support: enterprise support, incident comms, roadmap transparency.
Run the same conversation scenarios across candidates and compare apples to apples, including hard cases: long contexts, noisy audio, tool timeouts, and high concurrency bursts.
Step-by-Step: Standing Up a Real-Time Conversational Stack
- Define SLOs and scope. Specify TTFT, p95 response times, channels (web/voice), and compliance constraints. List top intents and which require tools.
- Choose a hosting approach. Based on data handling and team skills, decide on managed, VPC, on-prem, or hybrid. Pick regions near your users.
- Select models and routing. Start with a small router model, a mid-size main model, and an optional large model for escalations. Decide on quantization and adapters.
- Implement RAG minimally. Build an ingestion pipeline, embed content, tag metadata, and wire a fast vector search. Add reranking only if needed.
- Add voice (if needed). Integrate streaming ASR and TTS; test barge-in and echo cancellation. Co-locate compute near telephony ingress.
- Build orchestration with streaming. Use a graph that supports token streaming across nodes, timeouts, and retries.
- Instrument everything. Collect TTFT, tokens/sec, retrieval latency, tool timings, cache hits. Create dashboards and alerts.
- Harden for production. Configure autoscaling, warm pools, health checks, and circuit breakers. Write runbooks and test failovers.
- Ship pilots and iterate. Run canaries, gather user feedback, A/B prompt templates, adjust routing thresholds.
- Optimize cost. Tune prompts, enable caching, calibrate batching, and renegotiate vendor rates once patterns stabilize.
Future Direction: Multimodal, Agents, and On-Device Acceleration
The line between chatbots and full agents is blurring. Multimodal models can see, hear, and speak; agents chain tools to complete tasks end-to-end. Hosting platforms are evolving to support action safety, memory stores, and event-driven orchestration where multiple specialized models collaborate.
Expect broader use of speculative decoding, KV-cache sharing across requests, and fine-grained memory policies that keep experiences fast while respecting privacy. On the edge, NPUs in phones and laptops will enable partial on-device inference—fast ASR/TTS or small-model planning—while handing complex reasoning to regional GPUs.
Finally, governance will mature: standardized redaction APIs, lineage tracking for prompts/responses, and auditable playbooks for incident response involving AI.
FAQs
Q.1: What’s the single biggest factor that determines whether my conversational AI “feels” real-time?
Answer: Perceived latency is dominated by time-to-first-token (TTFT) and streaming. If your user sees or hears a response quickly—even a greeting or partial sentence—the experience feels responsive.
Achieving a low TTFT is a combination of model choice, warm instances, compact prompts, and fast retrieval. For voice, you also need streaming ASR and TTS so partial transcriptions and speech chunks arrive continuously.
Many teams fixate on total completion time, but the human brain is more forgiving of longer tails if the system starts responding promptly and keeps a steady cadence.
Instrument TTFT p95 as a first-class SLO and design your architecture to protect it with warm pools, short prompt templates, and dynamic routing that avoids heavy models for trivial intents.
Another underappreciated factor is tail latency from tools. A single slow CRM or knowledge API can blow your budget even if the model is fast. Place circuit breakers around tools, cache stable outputs, and consider “answer now, enrich later”: stream a concise answer first and append details after the tool returns.
This pattern keeps conversations flowing while still providing accurate, grounded information. Lastly, put computers near users or telephony ingress; shaving a 100 ms RTT can be the difference between “snappy” and “laggy,” especially for voice.
Q.2: Do I need retrieval-augmented generation (RAG) for my first launch, or can I start without it?
Answer: You can absolutely launch without RAG for narrow, transactional bots or for use cases where the model’s built-in knowledge is enough. In early pilots, it’s often better to ship a minimal stack—a good base model, clear system prompts, and a couple of well-defined tools—than to over-engineer a sprawling retrieval layer.
That said, if your assistant must reference dynamic or proprietary knowledge (pricing, policies, product specs), RAG becomes essential to maintain accuracy and reduce hallucinations.
The trick is to start small: ingest the top FAQs and critical docs, use compact chunks, and set a tight top-K. Measure whether reranking meaningfully improves answers relative to its latency cost; don’t assume you need it on day one.
As your footprint grows, RAG pays off by localizing knowledge updates. You can refresh embeddings when content changes without touching model weights, keeping responses current. It also allows tenant isolation: each customer or department can have its own vector index and permissions.
Remember to keep your prompt budget under control—short, relevant context beats long, generic dumps. If your latency SLOs are strict (voice), consider a two-step pattern: quick intent classification and canned answers for known queries, with RAG reserved for tougher cases where users tolerate an extra second.
Q.3: How should I think about costs as usage scales—what are the biggest levers?
Answer: Your three biggest cost levers are model selection, prompt size, and caching. Use the smallest model that meets quality for the majority of traffic; reserve larger models for complex or high-value queries via routing.
Keep prompts lean: every extra token increases both cost and TTFT. Summarize conversation history, limit retrieval to the top few passages, and prefer structured tool outputs over verbose prose inside the context window.
Caching can be transformative—cache embeddings, retrieval hits, tool outputs for stable data, and even full responses for high-frequency questions. Many managed platforms also offer prompt/result caching discounts, which effectively turn repeat questions into pennies.
Operational tactics matter too. Adopt autoscaling with class separation: interactive queues get minimal batch waits and reserved capacity; async/reporting jobs use cheaper, larger batches (or spot GPUs).
Quantization and speculative decoding increase throughput per GPU, lowering unit cost. Finally, negotiate pricing once patterns stabilize—committed-use discounts or enterprise plans reduce volatility.
Track costs per tenant/intent so you can prune expensive outliers, and run periodic “cost-quality” audits to ensure you’re not using a heavyweight model where a smaller one suffices.
Q.4: Is on-prem hosting worth it for real-time agents, or should I stay in the cloud?
Answer: On-prem shines when data sovereignty, regulatory constraints, or integration with on-site systems (e.g., call centers, factories, retail) outweigh the operational complexity.
You gain tight control over data flows and can place the computer physically close to your telephony or POS systems, cutting RTT and improving voice responsiveness. However, you take on hardware lifecycle management, capacity planning, driver/toolkit compatibility, and 24/7 incident response.
Cloud providers and managed AI platforms deliver rapid iteration, easier scaling, and access to the latest model optimizations without kernel surgery. For many teams, a hybrid model is best: keep sensitive preprocessing and logs in your VPC or on-prem, but leverage managed inference for general chat or burst capacity.
If you choose on-prem, budget for observability and automation from day one: bare-metal Kubernetes (or a well-supported distro), GPU operators, image registries, IaC, and robust backup/restore.
Establish vendor support for your hardware stack. Most importantly, pilots with realistic traffic and voice paths; WAN quirks inside corporate networks can surprise you.
If your real need is just “data shouldn’t train public models,” note that many managed vendors support ephemeral retention and enterprise DPAs—you might get the compliance you need without taking on full ops responsibility.
Q.5: What’s the safest way to add voice (ASR/TTS) without blowing up latency?
Answer: Start with streaming everywhere: capture audio frames on the client and stream to your ASR as they arrive; process partial transcripts and pass them to the LLM without waiting for end-of-utterance.
In parallel, prepare TTS to speak as soon as the first tokens are generated—don’t block on complete responses. Place the computer near your telephone or WebRTC ingress to minimize RTT.
Choose ASR/TTS with low start-up and chunk latencies, and test under real network conditions (jitter, packet loss). Implement barge-in: when the user starts talking, pause or cut TTS and feed the live audio into ASR, resuming the turn-taking naturally.
Operationally, separate your voice “fast lane” from general chat: enforce stricter prompt budgets, avoid slow tools, and pre-warm model replicas. Log per-stage timings (ASR partial delay, TTFT, TTS first-chunk latency) and alert on regressions.
To handle accents and noise, tune ASR models with domain audio or add a lightweight noise suppression step at the edge.
Finally, plan fallbacks: if TTS fails, play a short apology tone or message rather than silence; if ASR confidence drops, ask the user to repeat with a clarifying prompt. Voice users are sensitive to flow—smooth interruptions and quick feedback trump perfect wording.
Conclusion
Hosting platforms are the foundation of real-time conversational AI. The best experiences come from aligning your latency SLOs, data constraints, and budget with an architecture that streams early and often, routes intelligently, and degrades gracefully when dependencies wobble.
Whether you choose a managed AI cloud for speed, a VPC deployment for control, an on-prem cluster for sovereignty, or a hybrid of all three, success hinges on the same fundamentals: compact prompts, fast retrieval (only when needed), warm and right-sized model pools, streaming ASR/TTS for voice, and strong observability that makes TTFT and tail latency visible and actionable.
Treat your model graph as a living system—canary changes, collect real feedback, and run cost-quality reviews regularly.
With the patterns in this guide, you’ll not only make your assistant sound smart—you’ll make it feel instant, dependable, and respectful of users’ time and data. That is the real bar for “real-time,” and with the right hosting platform, it’s absolutely within reach.