
By hostmyai September 29, 2025
Deep learning has revolutionized industries ranging from healthcare and finance to autonomous driving and natural language processing. However, the success of deep learning models relies heavily on computational power.
Training a state-of-the-art model such as GPT, ResNet, or BERT involves billions of parameters and terabytes of data, which makes traditional computing insufficient. This is where GPUs (Graphics Processing Units) come into play.
GPUs excel at parallel computation, a fundamental requirement for matrix multiplications and tensor operations at the heart of neural networks. But when your dataset and model grow larger than a single GPU can handle, you need to scale GPU instances effectively.
Scaling GPU instances means using multiple GPUs, often across different nodes, to speed up training time, handle larger batch sizes, and optimize resources. This process, while powerful, involves challenges like synchronization overhead, communication bottlenecks, and cost optimization.
In this guide, we’ll take a deep dive into scaling GPU instances for deep learning training, exploring the strategies, frameworks, and best practices for researchers, startups, and enterprises.
Understanding the Basics of GPU Scaling

Before diving into scaling strategies, it’s critical to understand what GPU scaling means in the context of deep learning. At its core, GPU scaling involves distributing your training workload across more than one GPU to accelerate computation or handle models too large for a single GPU’s memory.
There are two primary forms of scaling: vertical scaling and horizontal scaling. Vertical scaling refers to upgrading to a more powerful GPU with larger memory and more CUDA cores (e.g., moving from NVIDIA T4 to A100).
Horizontal scaling, on the other hand, means using multiple GPUs—either on the same machine or distributed across clusters. Horizontal scaling is the more sustainable long-term solution because even the most powerful single GPU eventually reaches its limits for modern models.
When scaling, developers also need to understand the difference between data parallelism and model parallelism. In data parallelism, each GPU processes a different subset of the dataset, and then gradients are aggregated to update the global model.
Model parallelism, by contrast, splits the model architecture itself across GPUs—useful for extremely large models that cannot fit into one GPU’s memory.
An important challenge with GPU scaling is communication overhead. When GPUs need to synchronize parameters after each batch, the cost of communication can sometimes outweigh the benefit of parallelism.
This is why frameworks like NVIDIA NCCL (NVIDIA Collective Communications Library) and hardware solutions like NVLink have become essential.
Another aspect of GPU scaling involves cloud providers. Platforms such as AWS, Google Cloud, and Azure offer GPU clusters with on-demand scalability. They allow researchers to scale horizontally with minimal upfront infrastructure investment, but managing costs becomes a vital concern in such environments.
In summary, scaling GPU instances is not merely about adding more GPUs; it requires an understanding of data distribution, communication strategies, memory management, and cost efficiency. With this foundation, let’s explore strategies to scale GPU workloads effectively for deep learning.
Data Parallelism in Deep Learning
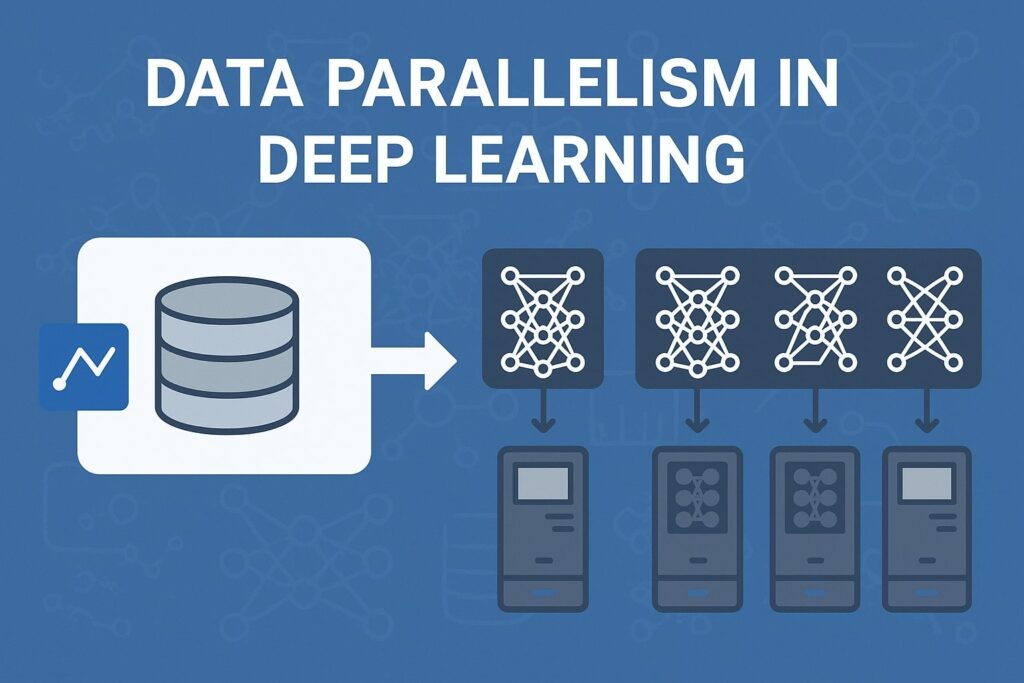
One of the most common strategies for scaling deep learning workloads across multiple GPUs is data parallelism. This approach divides the dataset into smaller mini-batches, with each GPU processing a different portion simultaneously.
After completing its forward and backward passes, each GPU computes gradients for its mini-batch. These gradients are then averaged (or summed) across GPUs, and the model’s parameters are updated accordingly.
The strength of data parallelism lies in its simplicity and scalability. It is especially effective when you have large datasets and models that fit within a single GPU’s memory.
Instead of a single GPU processing one mini-batch at a time, multiple GPUs process many mini-batches concurrently, drastically reducing training time.
A critical component of data parallelism is gradient synchronization. In synchronous training, all GPUs must finish their batch before gradients are averaged, which ensures consistency but may cause idle time for faster GPUs.
In asynchronous training, GPUs work independently and update shared parameters without waiting, which increases efficiency but risks inconsistencies or stale gradients. Most modern frameworks rely on synchronous data parallelism because of its stability.
Another factor to consider is batch size scaling. As the number of GPUs increases, the effective batch size also increases. While this can improve stability and gradient estimation, it may require careful tuning of the learning rate.
The “linear scaling rule” often applies: if the batch size doubles, the learning rate should also be scaled proportionally. However, this is not always perfect in practice, and techniques like learning rate warmup are used to stabilize training.
Popular deep learning frameworks like TensorFlow (tf.distribute.Strategy), PyTorch (DistributedDataParallel), and Horovod provide built-in support for data parallelism. NVIDIA’s NCCL ensures fast gradient reduction across GPUs, minimizing bottlenecks.
In conclusion, data parallelism is usually the first step when scaling deep learning models. It provides a balance of simplicity, efficiency, and scalability. But as models grow into billions of parameters, fitting even a single model replica on one GPU becomes impossible, which leads us to model parallelism.
Model Parallelism for Large Models
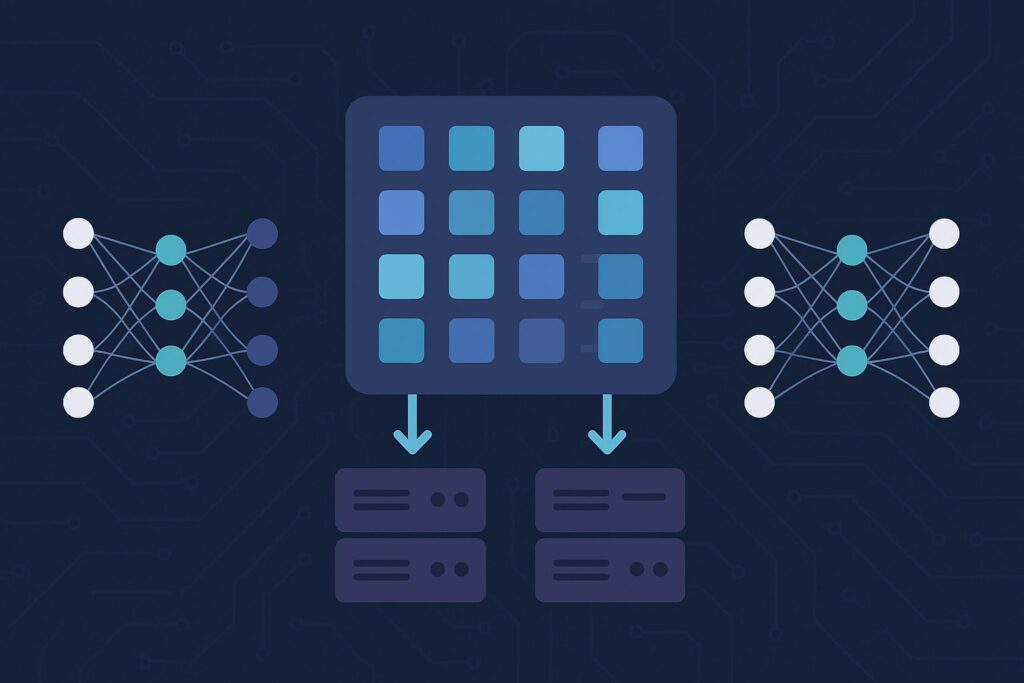
As models continue to grow—think GPT-3 with 175 billion parameters—data parallelism alone is not enough. Even with large-memory GPUs like the A100 (80GB), some models cannot fit on a single device. This is where model parallelism becomes essential.
In model parallelism, the architecture of the model is split across multiple GPUs. For example, the first few layers might run on GPU 1, while subsequent layers are placed on GPU 2, and so forth.
During training, the input passes sequentially through the GPUs, with intermediate activations transferred between devices. This approach enables training models that exceed the memory capacity of a single GPU.
There are different types of model parallelism:
- Layer-wise parallelism: Different layers of the model are placed on different GPUs.
- Tensor parallelism: Splits individual weight matrices or tensors across GPUs, distributing even a single layer’s computation.
- Pipeline parallelism: Breaks training into stages like an assembly line, where each GPU processes a portion of the pipeline concurrently.
A major challenge in model parallelism is communication overhead between GPUs. Since activations must be passed across devices, interconnect speed becomes crucial. This is why high-bandwidth solutions like NVLink, Infiniband, or dedicated interconnects in cloud clusters are vital.
Frameworks like DeepSpeed (Microsoft) and Megatron-LM (NVIDIA) specialize in model parallelism, allowing developers to train trillion-parameter models by combining tensor, pipeline, and data parallelism into hybrid approaches.
While model parallelism enables groundbreaking models, it is more complex than data parallelism. Careful partitioning of layers, tuning batch sizes, and minimizing inter-GPU communication are required for efficient training.
Moreover, pipeline parallelism introduces issues like pipeline bubbles, where GPUs idle while waiting for others to complete their stage. Solutions like micro-batching help mitigate this.
In short, model parallelism is essential for cutting-edge deep learning research where models push the boundaries of GPU memory limits. Though it introduces complexity, frameworks and optimized libraries are making it more accessible for researchers and engineers.
Hybrid Parallelism: Combining Strategies
Hybrid parallelism is a powerful concept that combines both data parallelism and model parallelism. In practice, most large-scale training systems, such as those used by OpenAI, Google, or Meta, rely on hybrid strategies to optimize performance.
The core idea is simple: use model parallelism to split huge models across GPUs, and then apply data parallelism to replicate those splits across multiple nodes. This allows for scaling not just within a single node but across entire clusters of GPU servers.
For example, a massive transformer model may use tensor parallelism to split each attention layer across four GPUs, while multiple replicas of this setup run in parallel using data parallelism. This way, both memory constraints and training time are addressed.
The challenge of hybrid parallelism lies in managing synchronization across multiple layers of parallelism. Gradient synchronization must occur not only across data-parallel replicas but also within model-parallel partitions.
Communication libraries like NCCL, MPI (Message Passing Interface), and frameworks like DeepSpeed or Horovod play a central role in ensuring synchronization happens efficiently.
Hybrid parallelism is not one-size-fits-all; the best configuration depends on factors such as model size, GPU memory, cluster topology, and interconnect bandwidth. Experimentation and profiling are key. Organizations often run extensive benchmarks before settling on an optimal hybrid parallelism strategy.
The benefits of hybrid parallelism are clear: faster training, support for ultra-large models, and efficient utilization of expensive GPU clusters. However, the added complexity requires a skilled engineering team to implement and manage.
As the field progresses toward trillion-parameter models, hybrid parallelism will remain the dominant scaling strategy. The synergy of splitting both data and models across GPUs ensures deep learning can continue pushing the limits of AI innovation.
Scaling in the Cloud: AWS, GCP, and Azure
Scaling GPU instances is not limited to on-premises hardware. Cloud providers such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer elastic GPU clusters designed specifically for deep learning workloads.
One of the biggest advantages of cloud scaling is flexibility. Instead of investing millions in data center hardware, startups and researchers can rent GPU instances as needed. This reduces upfront costs and allows scaling on-demand during peak training cycles.
- AWS: Offers EC2 P4 and P5 instances powered by NVIDIA A100 and H100 GPUs. With services like Amazon SageMaker, users can scale distributed training with minimal setup. Elastic Fabric Adapter (EFA) provides low-latency networking for multi-node GPU clusters.
- GCP: Provides A2 instances with A100 GPUs and TPU pods for specialized workloads. GCP integrates deeply with TensorFlow and supports Kubernetes-based scaling via GKE (Google Kubernetes Engine).
- Azure: Delivers ND and NC-series GPU VMs, optimized for training and inference. Azure Machine Learning simplifies distributed training workflows with automatic scaling features.
While cloud scaling provides accessibility, the main challenge is cost optimization. GPU instances are expensive, and costs can escalate quickly with long training runs. Strategies like spot instances, mixed-precision training, and profiling workloads help reduce costs.
Additionally, managed services like AWS SageMaker, GCP Vertex AI, and Azure ML abstract away much of the complexity, letting users focus on model design rather than cluster management.
Security and compliance also play roles in cloud scaling, especially in industries like healthcare or finance where sensitive data is involved. Cloud providers offer compliance certifications and secure networking options, but organizations must still implement proper encryption and data governance.
Ultimately, cloud GPU scaling democratizes access to high-performance computing. Whether you’re a solo researcher training models on Google Colab or an enterprise scaling on Azure’s NDv4 instances, the cloud provides powerful options to meet deep learning needs.
Cost Optimization in GPU Scaling
Training deep learning models at scale can be prohibitively expensive. A single A100 GPU instance may cost several dollars per hour, and multi-node clusters can run into thousands of dollars daily. Therefore, cost optimization is critical when scaling GPU instances.
Several strategies can help manage costs:
- Spot and Preemptible Instances: Cloud providers offer discounted GPU instances that can be interrupted at any time. By checkpointing training frequently, workloads can resume on new instances if preempted.
- Mixed-Precision Training: Using half-precision (FP16) instead of full precision (FP32) reduces memory usage and speeds up computation. NVIDIA’s AMP (Automatic Mixed Precision) enables this seamlessly.
- Gradient Checkpointing: Saves memory by re-computing intermediate results instead of storing them, reducing GPU memory requirements.
- Profiling Workloads: Tools like NVIDIA Nsight, TensorBoard, or PyTorch Profiler help identify bottlenecks and underutilized GPUs. Optimizing batch sizes, kernels, and memory usage ensures efficient GPU utilization.
- Elastic Scaling: Instead of running maximum cluster size at all times, dynamically adjust GPU usage based on workload requirements.
- Reserved Instances or Committed Use Discounts: For predictable workloads, committing to reserved GPU capacity lowers hourly costs.
Cost optimization is not just about reducing expenses; it’s about increasing ROI (Return on Investment). Efficient scaling ensures faster model development, quicker iterations, and ultimately, faster deployment to production.
Organizations that successfully balance performance and cost gain a competitive advantage in the AI race. By combining smart scaling strategies with financial discipline, GPU scaling becomes sustainable in the long term.
Best Practices for Scaling GPU Training
Scaling GPU instances successfully requires more than just adding hardware. It involves following best practices that optimize efficiency, reliability, and scalability.
- Start Small and Scale Gradually: Begin with a single GPU or node, profile performance, and scale incrementally. This helps identify bottlenecks early.
- Use Efficient Frameworks: Leverage frameworks like Horovod, DeepSpeed, or PyTorch Lightning that simplify distributed training and optimize communication.
- Leverage High-Bandwidth Interconnects: Ensure GPUs are connected via NVLink or Infiniband to reduce communication delays.
- Automate Checkpointing: Always save model states frequently to prevent loss from preemptible instances or hardware failures.
- Monitor Resource Utilization: Use tools like NVIDIA DCGM, Prometheus, or Grafana to track GPU usage, memory, and temperature.
- Optimize Hyperparameters for Scale: Adjust learning rates, batch sizes, and momentum to match larger distributed training setups.
- Test Fault Tolerance: Distributed training systems should gracefully recover from node failures. Fault tolerance ensures training resilience.
- Adopt Containerization: Using Docker and Kubernetes simplifies reproducibility, deployment, and scaling across environments.
By adhering to these practices, teams can ensure that GPU scaling not only accelerates training but also remains reliable, efficient, and cost-effective.
Frequently Asked Questions (FAQs)
Q.1: Why is scaling GPU instances necessary for deep learning?
Answer: Scaling GPU instances is essential because deep learning models are becoming increasingly large and complex. A single GPU, no matter how powerful, eventually runs into memory or computational bottlenecks.
For example, training models like GPT or large vision transformers require multiple terabytes of data and billions of parameters, which cannot fit into the memory of one GPU. By distributing workloads across multiple GPUs, training becomes not only feasible but also significantly faster.
Another reason for scaling is reducing time-to-market. In competitive industries, waiting weeks for a single training cycle is impractical. Multi-GPU scaling can cut training time from weeks to days or even hours, allowing organizations to iterate faster, test new hypotheses, and deploy solutions more quickly.
Q.2: What’s the difference between data parallelism and model parallelism?
Answer: Data parallelism splits the dataset across GPUs, where each device processes a portion of the data independently.
After each step, gradients are synchronized across GPUs to ensure consistent model updates. This approach is simple, widely supported, and highly effective for models that fit into a single GPU’s memory.
Model parallelism, on the other hand, divides the model architecture itself across GPUs. This is necessary for models too large to fit into one GPU, such as very large transformers or recommendation systems.
Each GPU handles different layers or parts of the network, and intermediate outputs are passed between devices. While more complex, model parallelism is indispensable for cutting-edge AI research.
Q.3: How do cloud providers support GPU scaling?
Answer: Cloud providers like AWS, Google Cloud, and Azure offer elastic GPU clusters where users can scale resources on demand.
These platforms provide specialized GPU instances powered by NVIDIA A100 or H100, optimized networking like NVLink or Infiniband, and managed services such as SageMaker, Vertex AI, or Azure ML.
The cloud also provides flexibility in terms of pricing models. Users can choose on-demand, reserved, or spot instances depending on workload predictability.
This means researchers and businesses can scale massively without investing in expensive hardware. However, effective cost management strategies are crucial to avoid runaway expenses when scaling in the cloud.
Q.4: How can I optimize costs when scaling GPU instances?
Answer: Cost optimization strategies include using spot instances, adopting mixed-precision training, checkpointing frequently, and profiling workloads to identify inefficiencies. For long-term predictable workloads, reserved instances or committed-use discounts can reduce costs significantly.
Another effective strategy is elastic scaling, where GPU resources are scaled dynamically depending on the training phase. For example, smaller clusters may be used during model prototyping, with larger clusters activated only for final training runs.
By adopting such strategies, organizations maximize return on investment while still benefiting from the power of large-scale GPU clusters.
Q.5: What are the challenges of scaling GPU training?
Answer: Scaling GPUs is not without challenges. The most common issues are communication overhead, where synchronizing gradients across GPUs becomes a bottleneck, and load imbalance, where some GPUs are underutilized compared to others.
Additionally, debugging distributed systems can be complex. Failures on one node may affect the entire training job. Engineers must also tune hyperparameters specifically for distributed environments, as large batch sizes and multiple GPUs can change training dynamics.
With proper frameworks, high-speed interconnects, and fault-tolerant design, many of these challenges can be mitigated.
Conclusion
Scaling GPU instances for deep learning training is both an art and a science. It requires balancing computational needs, memory constraints, and cost considerations while leveraging strategies like data parallelism, model parallelism, and hybrid parallelism.
Cloud providers further simplify scaling by offering elastic GPU clusters, but effective cost management remains essential.
As deep learning models continue to grow in size and complexity, scaling will remain a critical skill for researchers, engineers, and enterprises alike.
By adopting best practices, leveraging the right frameworks, and optimizing both performance and costs, organizations can unlock the full potential of large-scale deep learning.